This page is still being edited and reviewed.
Overview of the Converter functions
The purpose of the Chemotion Converter (in short: ChemConverter) is to convert different file formats and types from integrated devices to a common and well known data type, namely e.g. jcamp .jdx or .json. It is also possible to extract columns for 2D data visualization and Metadata. Currently, the ChemConverter can handle most text readable files like txt/csv/dta if they are properly structured, but developers can create their own readers if a rule is notable for the newly added file type.
Most of the time, the ChemConverter runs as a background process when the user or a measurement device uploads a analytic file to the ELN. The prerequisite is that an admin has created a suitable profile. There is also a standalone version of the converter which you can find and install from Github.
Technical aspect
Technically the converter is built based on three layers, namely the reader, the admin GUI and last but not least the upload & processing. The creator of reader requires mostly knowledge in (e.g python) coding while the admin of the second layer has to know the measurement technique and device very well, because it decides which info the use will get and see at the end of the third layer. The last layer is a simple Webapp executing the code or an automated process during the file upload. How the files are converted will be decided by specific rules which are listening on predefined identifiers.
First layer: The reader
The reader is one part of programming code responsible for the software to import and handle the given data format. It is the most powerful layer due to flexibility (e.g. calculation of custom Metadata or special and complex column rules and calculations).
Source codes for the readers and examples can also be found on Github. There are readers for common file types and specific ones which are heirs of the basic ones. The following list shows some (but not all) of the current readers available:
- ASCII (aka simple TXT)
- CSV
- NOVA (Specific reader for an instrument without Metadata, also an example for custom Metadata calculation)
- DTA
Second layer: The admin Profile creation GUI
The final rules to convert a data file into a standardized Bagit-it-zip-Container containing .jdx/.json files will be determined by profiles. Which profile is responsible is determined via identifiers. Like in case of the readers almost everything the input file contains can be used as an identifier, as long as the sum of identifiers for one profile is unique. The most common identifiers are:
- The file extension (.txt, .csv, .dta, ...)
- The first human readable line(s) of the header
- The data column titles
Purpose of the Profile GUI vs. Reader coding
The aim of the profiles is to give admin users, which are less or non-experience with Python Coding, the possibility to define rule sets for conversion. It's also possible to define different profiles using the same Reader but slightly different data files (e.g., if only one column is varying or two columns are mixed).
Third layer: Upload, processing and output
The normal user will only see the upload GUI, shown by the picture as standalone version (left) or inside the ELN (right).
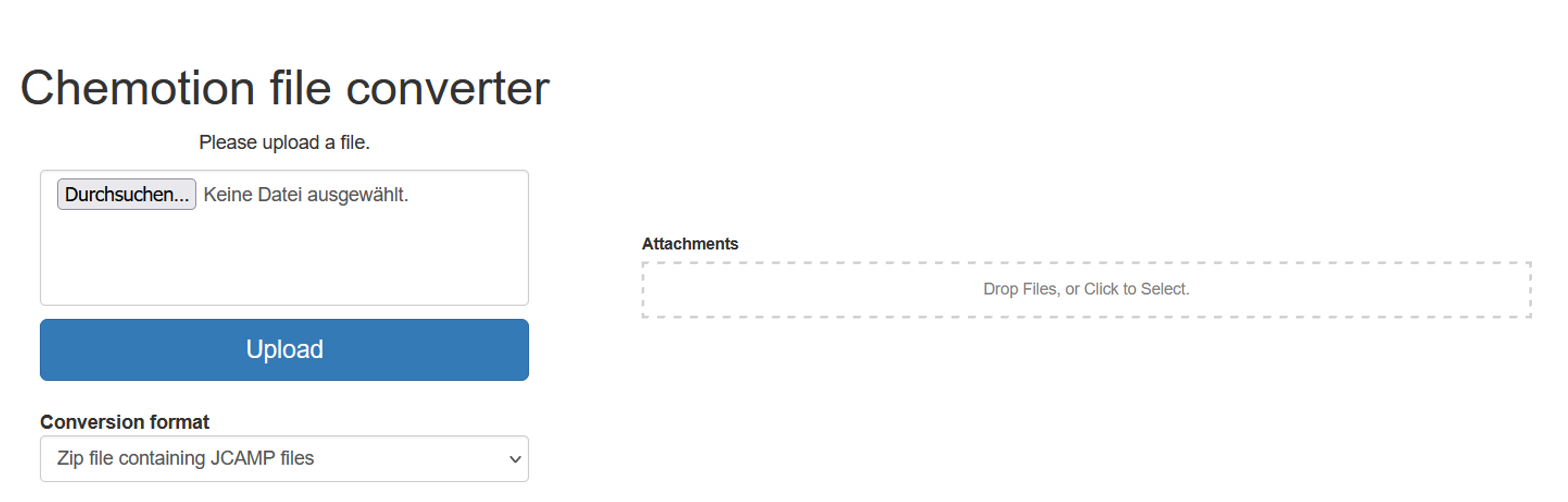
After the file is uploaded, it will be converted as long as there exists a suitable reader and profile. It's possible (via deep coding) to define which file types are redirected to the converter and which ones are only displayed as they are (e.g. in case of binary files like pictures) to evade errors from the Converter app.
Managing Profiles
The following section is important for privileged users and admins to help them manage their own adjustments and profiles.
Find existing profiles
If using the standalone version just write your "converter-URL"/admin/ into your browser's address bar. And if you are using the ELN integrated version you have to be logged in as an admin and click on the "Converter Profiles"-Tab on the left side. In both cases you will see the following GUI where all your profiles are listed (if there are already some of course):
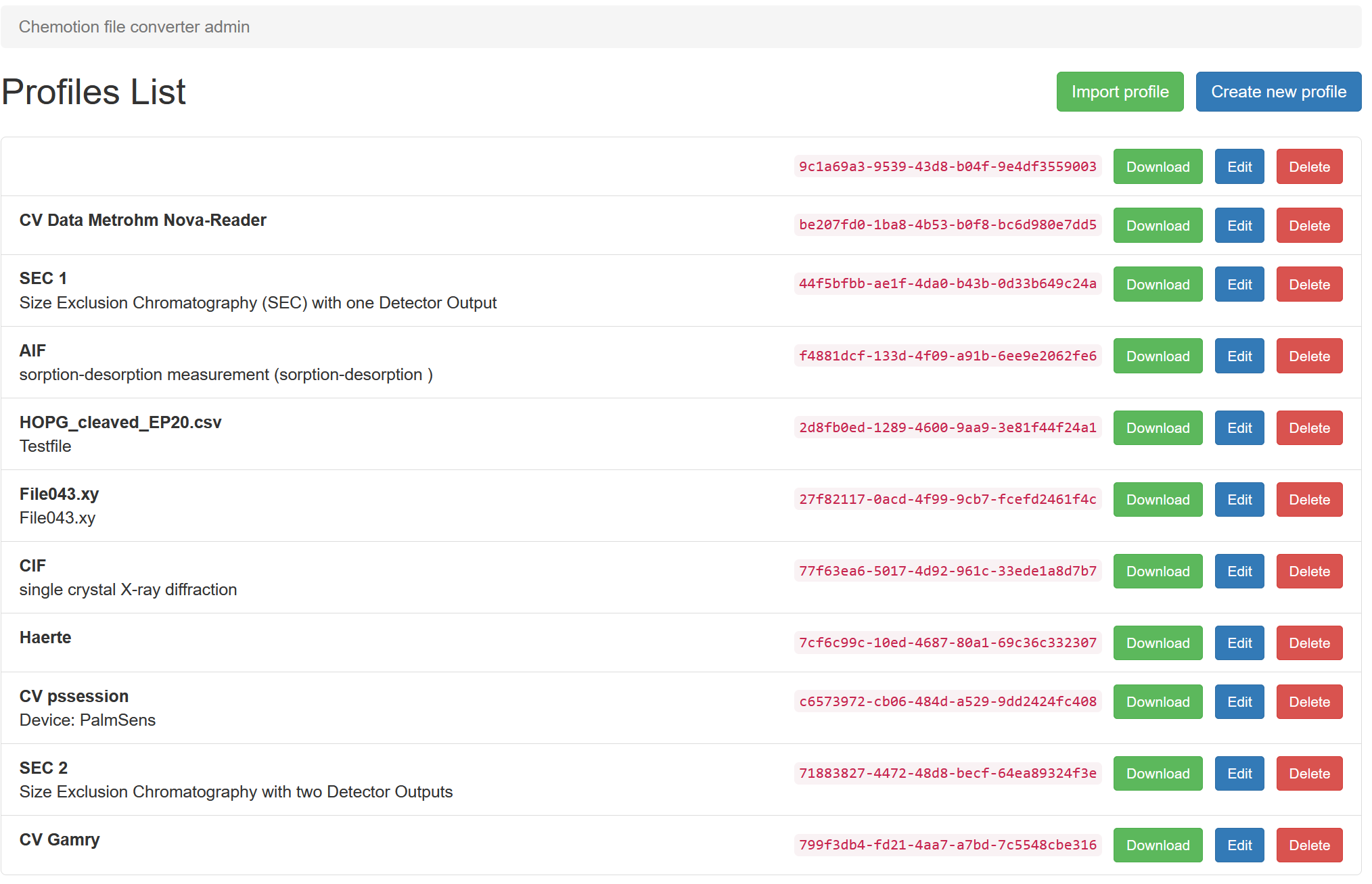
After clicking on the "Create new new profile"-Button you can finally start to ...
Create your own profile
To create a profile a first example file has to be uploaded. This file should be a maxima example with as much information as possible, even if later data files sometimes have fewer. The file type and it contents must fit to an existing reader or an error will occur. After the upload, the following default GUI will be shown:
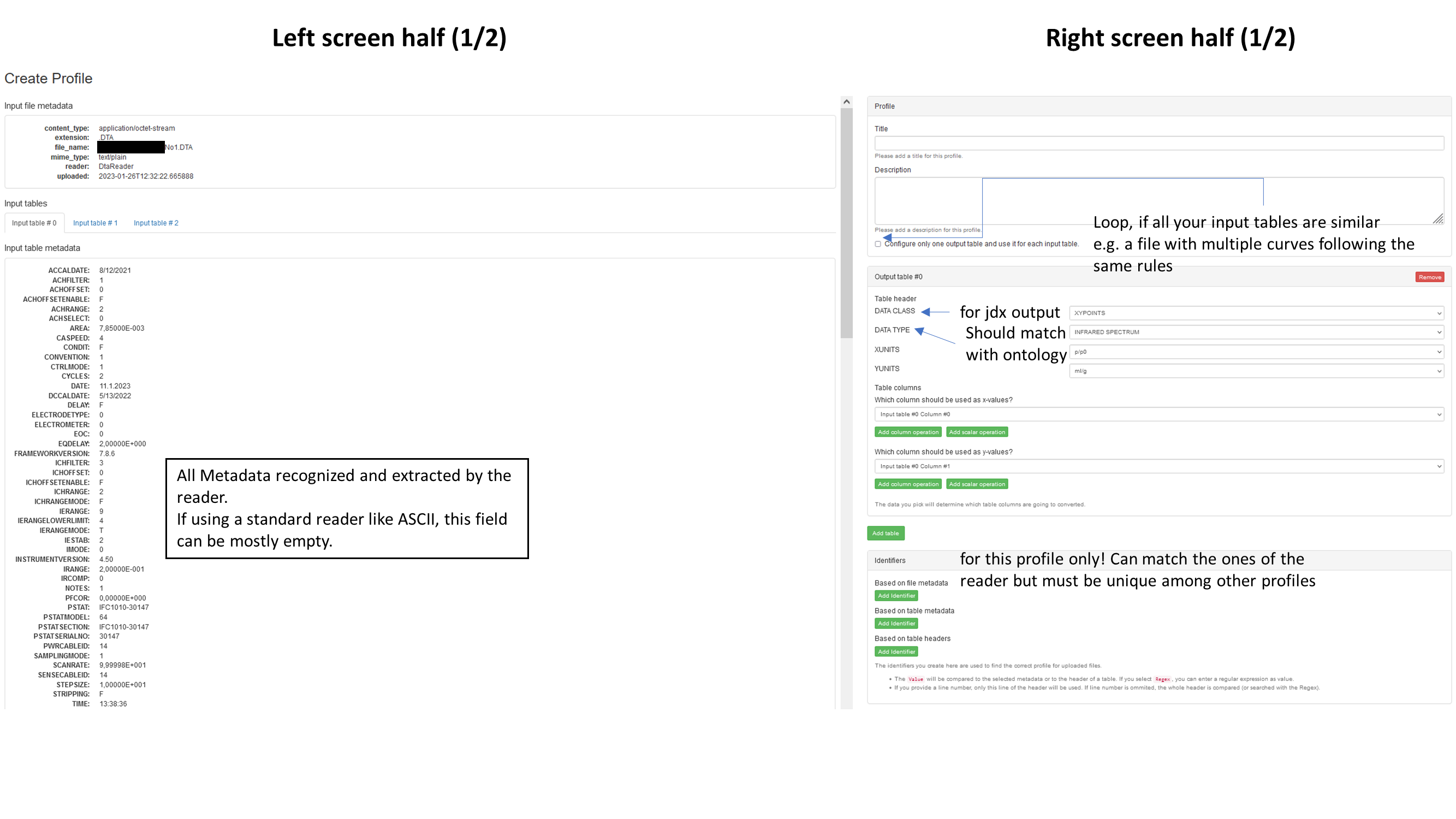
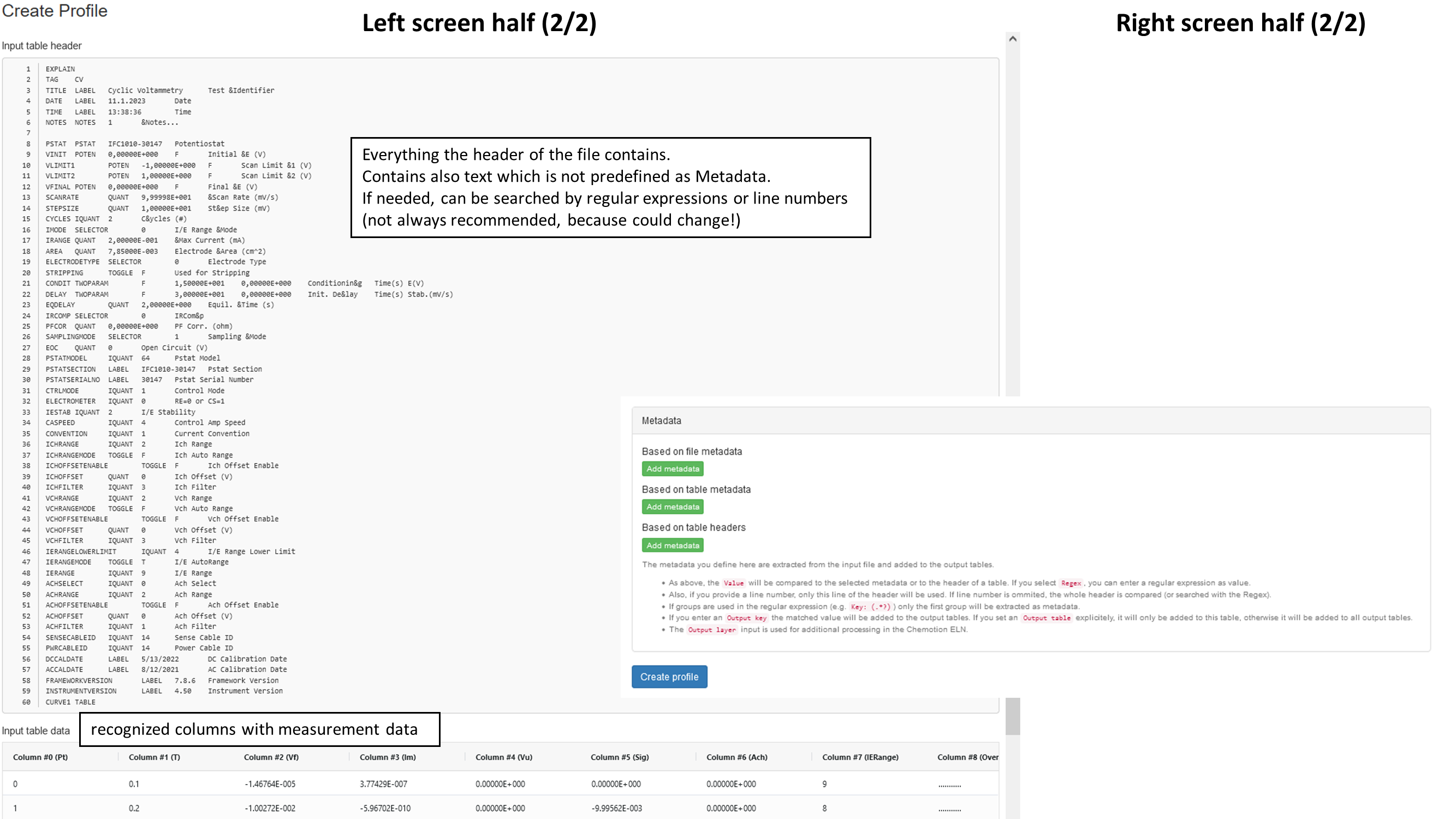
After all the adjustments and settings are done, the "Create profile" button will finish the job and the screen will be back to the existing profiles page. Now a non-admin user or an automatic process can upload and convert files.
Specific settings
Data Class
The "Data Class" drop down menu defines the kind of jdx output. Currently there are four used classes:
| Data Class | description | requirements |
|---|---|---|
| XY POINTS | typical "modern data curves" where each data point is described by two coordinates (x and y). Difference between each x need not to be equal | exactly one column with x values & one column with y values |
| XY DATA | Classical jcamp files with the intension to save hard drive space. Difference between each x is always equal. | exactly one column with y values and defined values for FIRSTX, LASTX and DELTAX |
| PEAK TABLE | ||
| NTUBLES |
Data Type
A drop-down list of ontologies (mostly chemical analytic techniques) defining the kind of layout for displaying and plotting curves and spectra in ChemSpectra. Not all ontologies known in the ELN are findable here because it's only for layout purposes. If you think that something is missing, feel free to tell us.
X & Y Units
A list of physical units containing the most common units with and without prefixes. If you need additional units, please tell us or use the "scalar operation" feature to convert the column values.
Table columns
A drop-down menu for defining the x and y column values while a preview can be seen on the end of the left side as "Input table data". Currently only 2D data extraction is possible so if you need more, you can create additional Output tables and merge them together with external tools. Alternative you can use the "column operation" feature to add, subtract, divide or multiply columns together.
In a future version it will become possible to create profiles without Output tables if you intend to use the converter only for Metadata extraction.
Metadata and Identifiers
Both share some similarities, even in the backend (both are called "identifier" there), with the exception that Metadata have an assigned "optional = true" flag. Every info and content the file provides and which is not explicit declared as (measurement) data by the reader can been seen as Metadata. Metadata can often be further broken into "key & value". Sometimes the key is provided together with the value, which makes it easier for the reader to recognize the string as Metadata, and in other cases, it has to be defined or assigned by a user with background and RegEx knowledge. While creating a profile you have to assign one of three match parameters to the desired key.
| Match | behavior | default for |
|---|---|---|
| Exact Value | The value of the key will only be extracted or valid for profile choosing if it's the same as the one of the example file during profile creation. | Identifiers |
| Any Value | The value will always be extracted as long as the key is found in the given file. | Metadata |
| RegEx | The value from the input field is translated into a regular expression and compared to the string value from the input file. If the RegEx is valid, the first group of the result will be extracted as the value for the wanted key. | n.a. but often used for searching table headers with/-out line number |
The extraction and assignment is now done by text fields and drop-down menus. You just have to follow this steps:
- Press "Add Metadata/Identifier"
- Choose a key or table (+ optional line number) as input
- Choose on of three matches and if it is not "any", write a value or RegEx into the text field
- Choose an output layer (comparable with a category)
- Choose an output key
- Optional: add scalar Operators (+,-,*,:) to the calculation of your output
In the end, it could look like this:
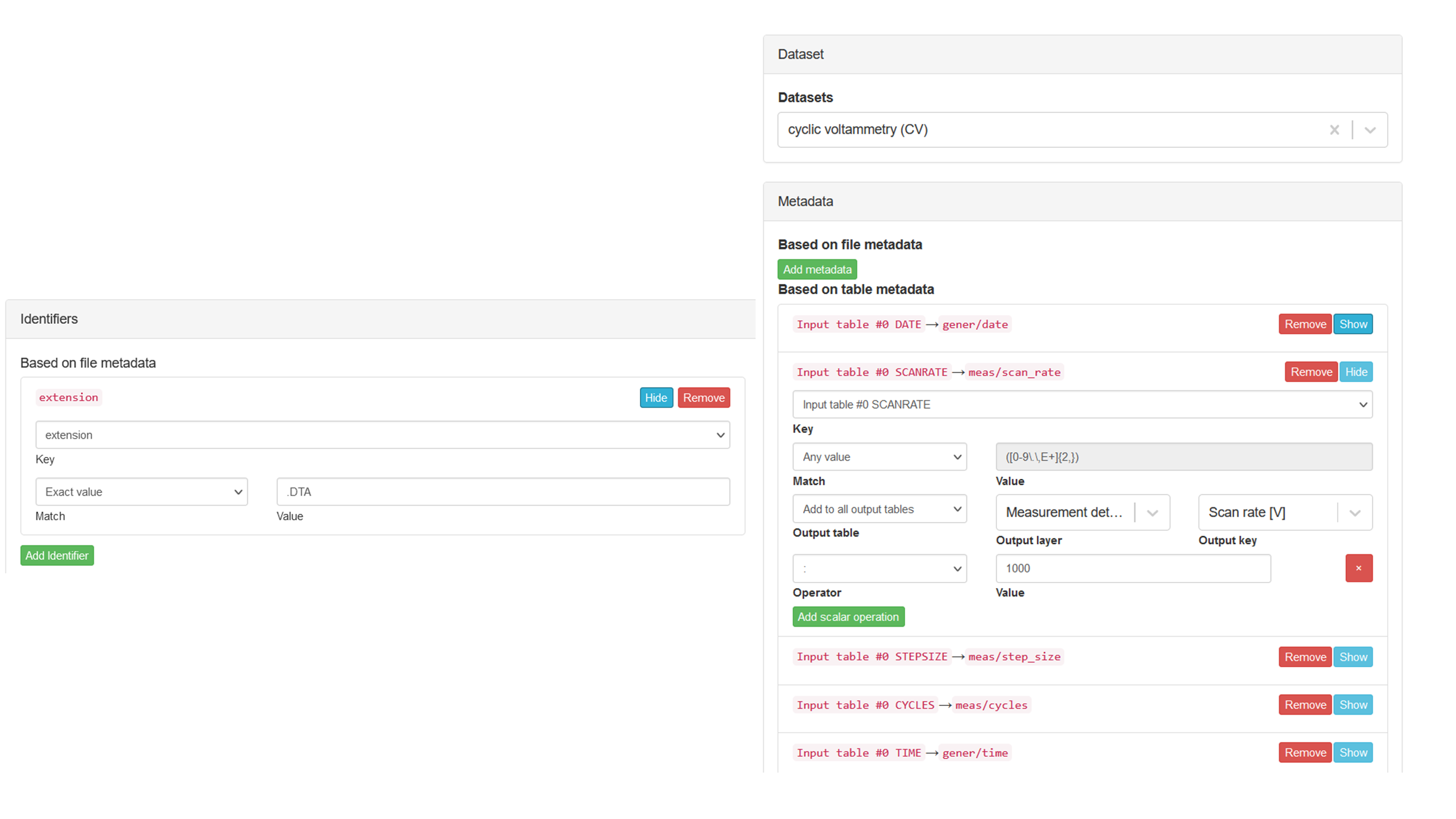
If the converter is integrated in the ELN and an already designed Dataset is chosen, bullet points 4 and 5 are chosen via drop-down menus otherwise typing a value is necessary.
Save
To finish your creation or save changes click on the "Create/Update profile" button or else everything will be lost.
Summary
The following picture shows the course of the three layers.
